
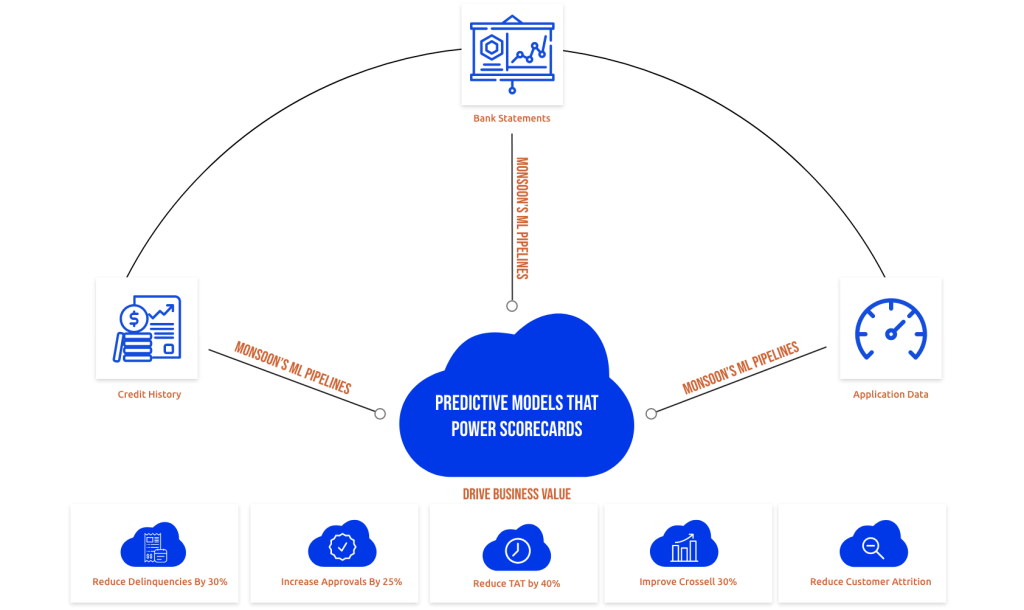
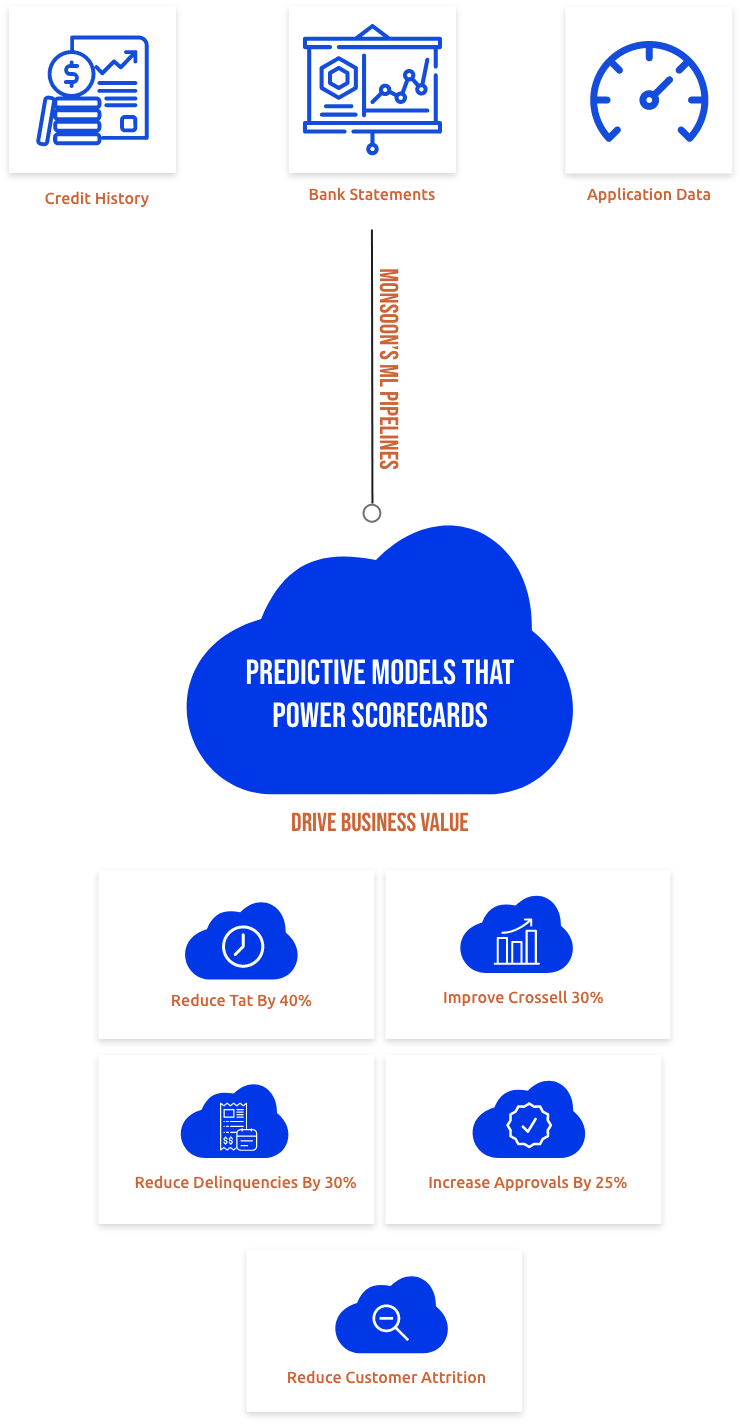

Data Analysis
Monsoon's proprietary pipelines analyze the uploaded data, check for information-leakage, analyze the data to high spot correlations and anomalous patterns within the data and prepare it for the next steps.

Modeling Strategy
Our pipelines crunch the data to build a range of modeling strategies from which the user can select. Good/bad-definitions, flag definitions, observation windows, inclusion criteria - the user can pick from range of strategies..

Feature Engineering
Monsoon's feature engineering pipeline uses a unique blend of domain knowledge and statistical inferencing to build thousands of features from each dataset capturing complex patterns that link data with response variables.

Feature Selection
Our state-of-the-art feature selection pipelines , some of which are proprietary, can distinguish between noise and genuinely powerful features that hold across time and sample. Only these features are selected for the final model.

Modeling
After optimizing hyperparameters over massive search spaces, multiple models are built and ensembled, optimizing a specific function picked from a range of cost-functions to achieve a "fit" with the business problem..

Validation
The candidate models are then validated across time and sub-sample to ensure that not only does the final model perform well across time, but that it also works well across different segments of the population it is being built for..

ML Model
The final model that is picked by our pipelines is then tested thoroughly to ensure that all constraints around latency, size, response and target deployment environments are catered to adequately..
Data Analysis
Monsoon's proprietary pipelines analyze the uploaded data, check for information-leakage, analyze the data to high spot correlations and anomalous patterns within the data and prepare it for the next steps.
Modeling Strategy
Our pipelines crunch the data to build a range of modeling strategies from which the user can select. Good/bad-definitions, flag definitions, observation windows, inclusion criteria - the user can pick from range of strategies.
Feature Engineering
Monsoon's feature engineering pipeline uses a unique blend of domain knowledge and statistical inferencing to build thousands of features from each dataset capturing complex patterns that link data with response variables.
Feature Selection
Our state-of-the-art feature selection pipelines , some of which are proprietary, can distinguish between noise and genuinely powerful features that hold across time and sample. Only these features are selected for the final model.
Modeling
After optimizing hyperparameters over massive search spaces, multiple models are built and ensembled, optimizing a specific function picked from a range of cost-functions to achieve a "fit" with the business problem.
Validation
The candidate models are then validated across time and sub-sample to ensure that not only does the final model perform well across time, but that it also works well across different segments of the population it is being built for.
ML Model
The final model that is picked by our pipelines is then tested thoroughly to ensure that all constraints around latency, size, response and target deployment environments are catered to adequately.
